 “Transformer models don’t require a fixed sequence length.” Since most of my projects revolve around computer vision, this was very confusing to me. In computer vision models, images are always preprocessed to a fixed size before being fed into deep learning models. Otherwise, you will encounter matrix multiplication error. In this post, we will learn how transofrmer handles variable-length sequnces.
“Transformer models don’t require a fixed sequence length.” Since most of my projects revolve around computer vision, this was very confusing to me. In computer vision models, images are always preprocessed to a fixed size before being fed into deep learning models. Otherwise, you will encounter matrix multiplication error. In this post, we will learn how transofrmer handles variable-length sequnces.
Self-attention - Q, K, V Linear Projection into Embedding Space
Let’s see basic CNN code example.
class SimpleCNN(nn.Module):
def __init__(self, input_channels=3, num_classes=10):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=input_channels, out_channels=16, kernel_size=3, padding=1) # (B, 16, H, W)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1) # (B, 32, H/2, W/2)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1) # (B, 64, H/4, W/4)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2) # Reduces spatial size by half
self.fc1 = nn.Linear(64 * 4 * 4, 128) # Assuming input images are 32x32
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
B, C, H, W = x.shape
x = x.view(B, C * H * W)
x = F.relu(self.fc1(x))
x = self.fc2(x) # Output logits
return x
B, C, H, W = 32, 3, 32, 32 # Batch of 32 RGB images (32x32 pixels)
num_classes = 10 # e.g., CIFAR-10 dataset
model = SimpleCNN(input_channels=C, num_classes=num_classes)
The line x = x.view(B, C * H * W) flattens height, and width dimension. If you pass input tensor torch.randn(B, C, 52, 33), you will see an error because self.fc1 layer is a matrix \(W \in \mathbb{R}^{128, 1024}\), which requires a specific feature dimension.
In natual langauge processing (NLP) mdoels, the input shape is \(B, N, C\) where \(N\) can be arbitrary. This type of input is called a variable-length sequence, which is more common in NLP. The model cannot handle variable-length input if the first dimension of nn.Linear weight matrix is \(N \times C\). Let’s see how transofrmer handle variable-length sequences during the self-attention.
class SelfAttention(nn.Module):
def __init__(self, embed_dim: int): # size is hidden size
super(SelfAttention, self).__init__()
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
def forward(self, input_tensor: torch.Tensor):
q, k, v = self.query(input_tensor), self.key(input_tensor), self.value(input_tensor)
scale = q.size(1) ** 0.5
scores = torch.bmm(q, k.transpose(1, 2)) / scale
scores = F.softmax(scores, dim=-1)
output = torch.bmm(scores, v)
return output
The weight matrices \(W_Q, W_K, W_V \in \mathbb{R}^{C, C}\) mean that nn.Linear does not expect the feature tensor to be flattened. Since the linear projection layer’s Q, K, and V matrix dimensions depend on the feature embedding dimensionn \(C\), there will be no multiplication error. The linear projection of Q, K, and V preserves the sequence length, allowing the model to handle variable-length inputs.
Self-attention - Padding and Masking
What about we include batch? Let’s say a batch sized four and forward pass to transformer.
- “This is a short sentence” \(N=7\)
- “This one is much longer and contains more words” \(N=8\)
- “Tiny” \(N=3\)
- “More words, more sequnces” \(N=6\)
The sequence lengths vary within the batch. You can’t feed this batch to the model due to inconsistent sequence dimension. Transformers require input of shape \(\mathbb{R}^{B \times T_{\text{max}} \times C}\) where \(T_{\text{max}}\) is the length of the longest sequence in the batch. We can simply address inconsistency by using padding. In our example, the longest sequence length within the batch is 8. We can add paddings to the shorter sequences so that all sequences have a uniform length of 8.
However, padding introduces irrelevant tokens that should not contribute to the model’s computations. To handle this, transformers use attention masks, which indicate which tokens are real and which are padding. Let’s see how self-attention is performed from the below image.
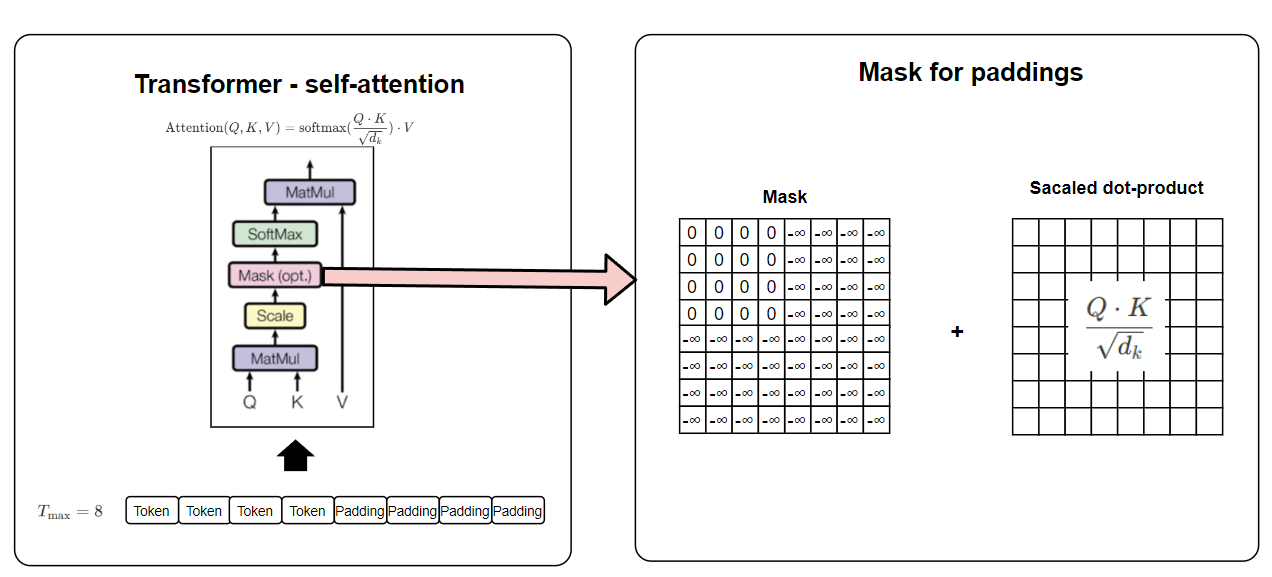
In the given image, we see how padding masks are applied to ensure that padded tokens do not interfere with the self-attention mechanism. Since attention scores are computed using a dot product of queries and keys, padding tokens would otherwise contribute to the output and affect model performance. By adding a mask filled with negative infinity (-∞) for padding positions, the softmax function effectively zeroes out their influence. This ensures that only meaningful tokens participate in the attention computation while maintaining a uniform sequence length across the batch.
Conclussion
Deep learning models don’t require strict input dimensions, but they do need careful design to handle variable-sized inputs effectively. By strategically using padding and attention masks, transformers can process sequences of different lengths without introducing errors in matrix operations. We learned how padding ensures uniform input sizes across a batch and how attention masks prevent padded tokens from affecting self-attention computations. Understanding these techniques is essential for efficiently training and deploying transformer-based models in NLP and beyond.