
In my last post, we explored how Segment Anything (SAM) works in image segmentation, breaking down the key components of its model architecture. SAM achieved great success in image segmentation, demonstrating two key strengths: its foundation as a large-scale model trained on an extensive dataset and its ability to be promptable, allowing users to generate segmentations with flexible inputs. These two strengths allow SAM to deliver impressive performance in a zero-shot setting. In Jul 2024, “SAM 2: Segment Anything in Images and Videos” was published. While SAM focuses solely on image segmentation, SAM2 takes things a step further. Not only does it improve performance in image segmentation, but it also introduces the ability to handle video segmentation, thanks to its own memory system. This enhancement allows SAM2 to track objects across frames, making it a powerful tool for dynamic and real-time applications. Personally, when I looked at SAM2’s zero-shot performance in tracking objects across video frames , I thought this could be a game-changer in the world of object tracking. In this article, we are gonna mainly talk about memory bank system of SAM2 as the rest of the parts are built on top of SAM.
SAM2 - Model Architecture
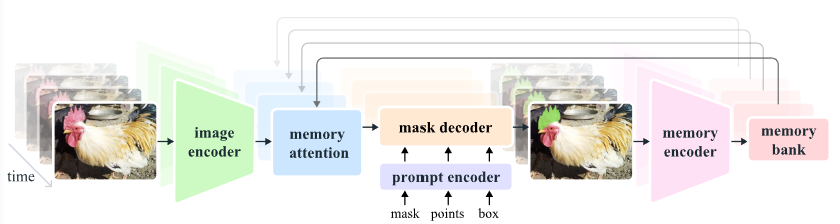 If you read my previous post, you might recognize some familiar components in the SAM2 architecture diagram: the image encoder, prompt decoder, and mask decoder—all key elements carried over from SAM. So, what’s new in SAM2? The introduction of three critical components: memory attention module, memory encoder, and memory bank.
If you read my previous post, you might recognize some familiar components in the SAM2 architecture diagram: the image encoder, prompt decoder, and mask decoder—all key elements carried over from SAM. So, what’s new in SAM2? The introduction of three critical components: memory attention module, memory encoder, and memory bank.
The memory encoder generates a memory by combining frame embedding and mask prediction across frames. The memory is sent to the memory bank, which retains the memory of past predictions for the target object. The memory attention module leverages the memory stored in the memory bank to enhance object recognition and segmentation across frames. These three components allows SAM2 to generate maskelt prediction, which means track of mask in a video. Even if you don’t provide prompts for the target object in the current video frame, SAM2 can still recognize and segment the target object based on previous prompts you provided in earlier frames. In addition, even if the target object is occluded in the past frame and reappears in the current frame, SAM2 can recover the segmentation.
Memory Encoder
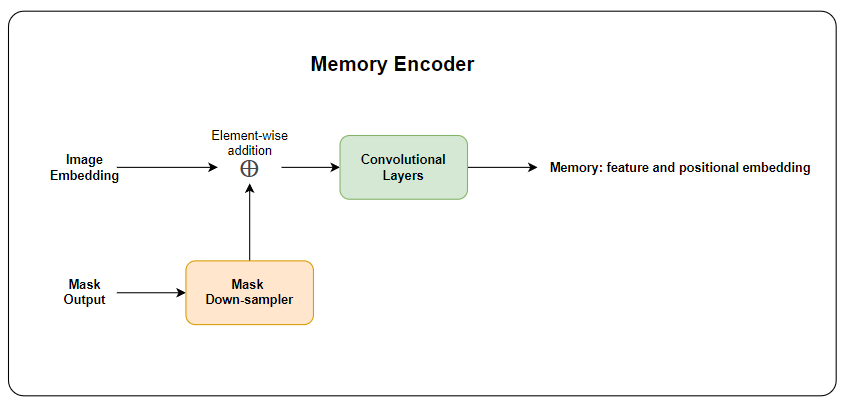 The Memory Encoder generates a memory representation by taking image embeddings and mask outputs as inputs. The image embedding \(I\) is produced by the image encoder, which processes the \(1024 \times 1024\) input image and embeds it into feature space. The mask output \(M\) is produced from the mask decoder. However, this mask does not come from the current frame—it is obtained from past frames. As the mask is a binary value tensor, it has one channel with the same height and width as input image (i.e. \(1 \times H \times W\)).
The dimensions for these two inputs are:
The Memory Encoder generates a memory representation by taking image embeddings and mask outputs as inputs. The image embedding \(I\) is produced by the image encoder, which processes the \(1024 \times 1024\) input image and embeds it into feature space. The mask output \(M\) is produced from the mask decoder. However, this mask does not come from the current frame—it is obtained from past frames. As the mask is a binary value tensor, it has one channel with the same height and width as input image (i.e. \(1 \times H \times W\)).
The dimensions for these two inputs are:
- Image Embedding \(I \in \mathbb{R} ^ {B \times 256 \times 64 \times 64}\)
- Mask Output \(M \in \mathbb{R} ^ {B \times 1 \times 1024 \times 1024} \)
As shown in the diagram, we need to perform element-wise addition between \(M\) and \(I\). We cannot add them directly because their dimensions are different. To resolve this, we use a down-sampler to project \(M\) into the same dimension as \(I\). However, element-wise addition alone is not sufficient to effectively combine these two inputs, as it only aligns them spatially without learning meaningful interactions. To better fuse the information from both inputs, the authors apply convolutional layers with a \(1 \times 1\) kernel, reducing the channel dimension. The generated memory \(\mathcal{M}\) will be used later in the memory attention module. In general, an attention mechanism requires not only an input feature but also its positional encoding to capture spatial relationships. Likewise, we need to compute the positional encoding of \(\mathcal{M}\) within the memory encoder block. Therefore, we have two outputs:
- Memory \(\mathcal{M} \in \mathbb{R} ^{B \times 64 \times 64 \times 64} \)
- Positional Embedding of Memory \(\text{PE}(\mathcal{M}) \in \mathbb{R} ^{B \times 64 \times 64 \times 64}\)
Refer to the implementation for details: mask encoder
Memory Bank
The memory bank consistently retains the first frame’s memory along with memories of up to N recent (unprompted) frames. Both sets of memories are stored as spatial feature maps.
First, let’s consider why the memory bank stores the first frame’s memory. SAM is an interactive segmentation model, meaning it requires a user’s prompt to generate predictions. Since prompts may not be provided for subsequent frames during inference, it is essential to retain the first frame’s prompt to ensure consistent segmentation across the video. The memory bank is given by:
\[\mathcal{B} = [\text{First Frame Memory | Recent N Frames Memory}] \]Each frame’s memory includes an object pointer, which is appended to its feature representation. First, the memory \(\mathcal{M}\) is reshaped from \(\mathbb{R} ^{B \times 64 \times 64 \times 64}\) to \( \mathbb{R} ^{B \times 4096 \times 64} \). The object pointer is added to \(\mathcal{M}\) such that
\[\mathcal{M} := [\mathcal{M}, \text{pointer}] \in \mathbb{R}^{B \times (4096 + 4) \times 64}\]where the object pointer has a length of four and is concatenated along the sequence dimension. The object pointer is generated by the mask decoder, providing a more compact and stable representation of the object across frames. More details can be found in the SAM2 paper.
In addition to the spatial memory, we store a list of object pointers as lightweight vectors for high-level semantic information of the object to segment, based on mask decoder output tokens of each frame. Our memory attention cross-attends to both spatial memory features and these object pointers. … Further, we project the memory features in our memory bank to a dimension of 64, and split the 256-dim object pointer into 4 tokens of 64-dim for cross-attention to the memory bank.
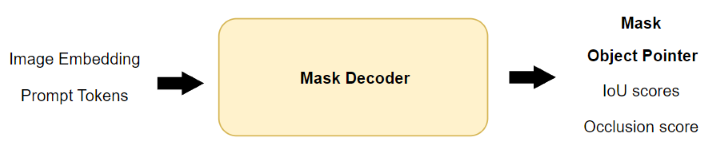
But you might ask, what is the use of an object pointer? Instead of relying solely on raw mask features from memory, object pointers provide a compressed representation of object instances. Consider an object that disappears behind another object for a few frames. If we only rely on spatial memory, the model might lose track of the object due to inconsistency between mask features across frames. In contrast, the object pointer provides a more stable and consistent representation of an object across frames.
There is no explicit class definition for the memory bank in the source code. However, we can infer its role from the logic in sam2_base.py, where past frame memories (both conditioned and non-conditioned) are stored and retrieved for memory attention. Note that the shape of memory bank \(\mathcal{B}\) changes based on current frame index and the number of memories \(N\) such that \(\mathcal{B} \in \mathbb{R}^{B \times (N) \cdot 4010 \times 64}\).
#sam2_base.py https://github.com/facebookresearch/sam2/blob/main/sam2/modeling/sam2_base.py
class SAM2Base(torch.nn.Module):
def __init__(...):
#...
self.num_maskmem = num_maskmem # Number of memories accessible
def _prepare_memory_conditioned_features(...):
#...
#list of memory per frame
for t_pos, prev in t_pos_and_prevs:
#...
to_cat_memory.append(feats.flatten(2).permute(2, 0, 1))
to_cat_memory.append(obj_ptrs)
memory = torch.cat(to_cat_memory, dim=0) #memory bank
#forward memory through memory attention module
pix_feat_with_mem = self.memory_attention(
curr=current_vision_feats,
curr_pos=current_vision_pos_embeds,
memory=memory,
memory_pos=memory_pos_embed,
num_obj_ptr_tokens=num_obj_ptr_tokens,
)
Memory Attention
The role of memory attention is to condition the current frame features on the past frames features and predictions as well as on any new prompts.
The authors used the term condition. So what does condition mean? Conditioning in this context refers to incorporating past frame embeddings (both image and mask-based features) into the processing of the current frame. But how?
The memory attention module utilizes both self-attention and cross-attention mechanisms. Through self-attention, the current frame embedding \(I\) attends to itself internally. Through cross attention, \(I\) attends to memory bank \(\mathcal{B}\), integrating information from past frames. The memory attention layer consists of a self-attention block, followed by a cross-attention block. The inputs to this layer are:
- Image Embedding \(I \in \mathbb{R}^{B \times\ 4096 \times 256}\)
- Image Positional Embedding \(\text{PE}(I) \in \mathbb{R}^{B \times\ 4096 \times 256}\)
- Memory Bank \(\mathcal{B} \in \mathbb{R}^{B \times N \cdot 4010 \times 64}\)
- Memory Bank Positional Embedding \(\text{PE}(\mathcal{B}) \in \mathbb{R}^{B \times N \cdot 4010 \times 64}\)
The diagram below shows a memory attention layer. For simplicity, normalization, dropout, and MLP layers are excluded from the diagram. By default, memory attention has four memory attention layers. Each layer first applies self-attention, allowing the current frame embedding to refine itself by attending to its own spatial features. Then, cross-attention enables the current frame to incorporate relevant information from the memory. As a result, the memory attention module outputs the conditioned frame feature:
\[I_{I|\mathcal{M}} \in \mathbb{R}^{B \times 4096 \times 256},\]which is subsequently used as input to the mask decoder, instead of unconditioned image embedding \(I\).
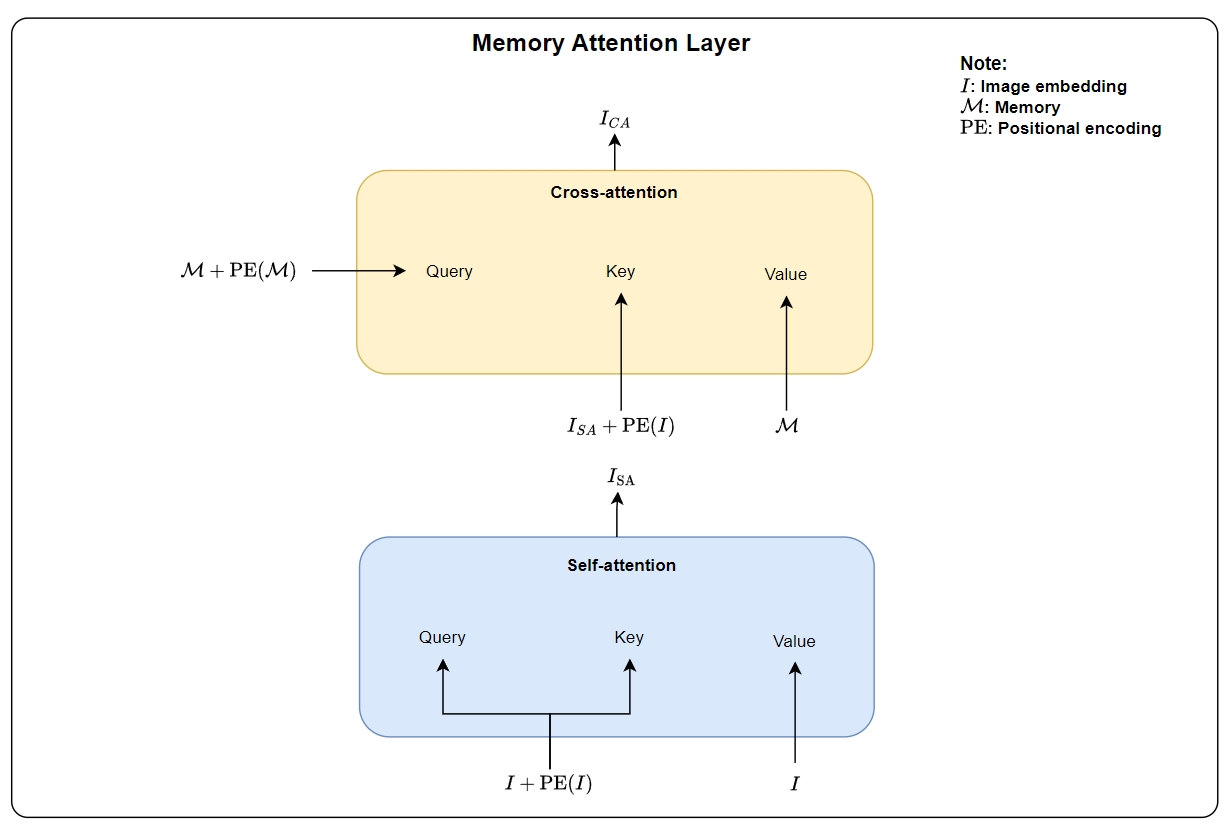
In the self-attention block, \(I + \text{PE}(I)\) for the query and key, while \(I\) is passed as the value. This raised a major question for me because, typically, the query, key, and value are the same—each being the input feature with added positional embedding. This query-key-value modeling was inspired from DETR (DEtection TRansformer).
It starts by computing so-called query, key and value embeddings after adding the query and key positional encodings - DETR
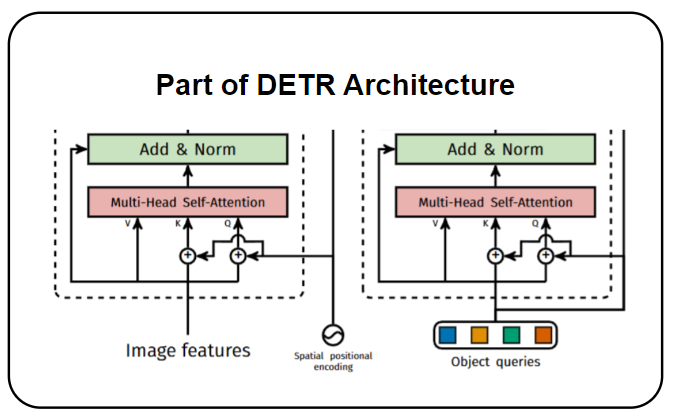
Positional encoding is essential for self-attention because transformers are inherently permutation-invariant—they lack an inherent sense of sequence order. By adding positional encoding to queries and keys, the model can learn spatial relationships and distinguish between positions. However, is it necessary to apply positional encoding to values if it doesn’t improve performance? If not, it would only introduce unnecessary computational overhead.
Conclusion
In this post, we reviewed the technical components of the memory encoder and memory attention module in SAM2. These components work in tandem to ensure consistent mask generation across video frames. The memory encoder captures past frame information, while the memory attention module conditions the current frame using stored memories. By retaining memory over time, the model can generate masks even in the absence of additional prompts. Moreover, the memory bank enables the model to handle occlusions, ensuring that objects remain identifiable even when temporarily hidden. This structured memory mechanism enhances segmentation robustness and adaptability in dynamic video environments. SAM2 represents a significant advancement in computer vision, particularly in video object segmentation. Its ability to maintain memory across frames and handle occlusions makes it a powerful tool for various applications. Given its robust performance, we can expect to see widespread adoption of SAM2 in fields such as medical imaging, autonomous driving, and video editing.