A tokenizer converts natural language into a sequence of tokens. Among these tokens are special tokens, which are not regular words but serve specific functions for the model (e.g., <BOS> and <EOS>). While reviewing academic literature on LLMs and VLMs, I came across several studies that introduce new special tokens to enhance model capabilities. In this blog, we’ll explore what special tokens are in LLM tokenization and, more importantly, examine when and why researchers choose to add new special tokens.
Special Tokens in General
 A tokenizer breaks text into smaller parts, called tokens. Each token has its own unique ID. Based on the number of token IDs, the vocabulary size of the tokenizer defines how many unique tokens it can represent.
A tokenizer breaks text into smaller parts, called tokens. Each token has its own unique ID. Based on the number of token IDs, the vocabulary size of the tokenizer defines how many unique tokens it can represent.
A special token is a token that is not a regular word but serves a specific function in helping the model understand or manage the text. Of course, a special token also has its own unique ID. Special tokens can be used to:
- mark the beginning or end of a sequence of text (e.g.,
<BOS>and<EOS>). - separate different segments or parts (e.g. multi-turn conversation).
- indicate masked or unknown words during training and inference.
- introduce as placeholders for non-textual modality.
Let’s see the special tokens for Llama-3 tokenizer.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B")
print(tokenizer.special_tokens_map)
The above code prints {'bos_token': '<|begin_of_text|>', 'eos_token': '<|end_of_text|>'}. Meanwhile, the GPT-2 tokenizer has special tokens as follows: {'bos_token': '<|endoftext|>', 'eos_token': '<|endoftext|>', 'unk_token': '<|endoftext|>'}.
Now we see different LLMs use different tokenizers, resulting in different special tokens.
Special Token in Conversational Model
When new LLMs are released, they also release conversational model in addition to a base model. A conversational model is an instruction-tuned version of the base model designed to handle dialogue like ChatGPT. Qwen-chat and LLaMA-instruct are the well-known examples of conversational models.
Generally, the tokenizers of conversational models have additional tokens to guide conversation structure. These special tokens may indicate roles such as system, user, or assistant and help the model generate context-aware responses.
Let’s see the Qwen-chat tokenizer. The Qwen-chat tokenizer has special tokens as follow: {'eos_token': '<|im_end|>', 'pad_token': '<|endoftext|>', 'additional_special_tokens': ['<|im_start|>', '<|im_end|>']}. We see new special tokens <|im_start|> and <|im_end|>. <|im_start|> indicates input message start and <|im_end|> indicates input message end.
So if we gives input like this:
[
{ role: "user", content: "Hi there!" },
{ role: "assistant", content: "Hi there, how can I help you today?" },
{ role: "user", content: "I'm looking for a new pair of shoes." },
]
, the tokenizer sees the input like this:
<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Hi there, how can I help you today?<|im_end|>
<|im_start|>user
I'm looking for a new pair of shoes.<|im_end|>
Take a look at Hugging Face post, if want to know about special tokens with chat conversation template.
Special Tokens for Non-textual Modality
This is the reason why I wrote this blog post. While reading papers on multimodal LLMs, I noticed that several studies add new special tokens to support their tasks. In this section, we will see how these papers utilize new special tokens.
Special Tokens for Interleaved Data
Flamingo is one of the earliest works in multimodal LLMs. Throughout their paper, the authors mention “interleaved” many times. Interleaved data refers to a sequence of text tokens mixed with visual tokens. The image below shows how real-world interleaved data is converted into tokens.
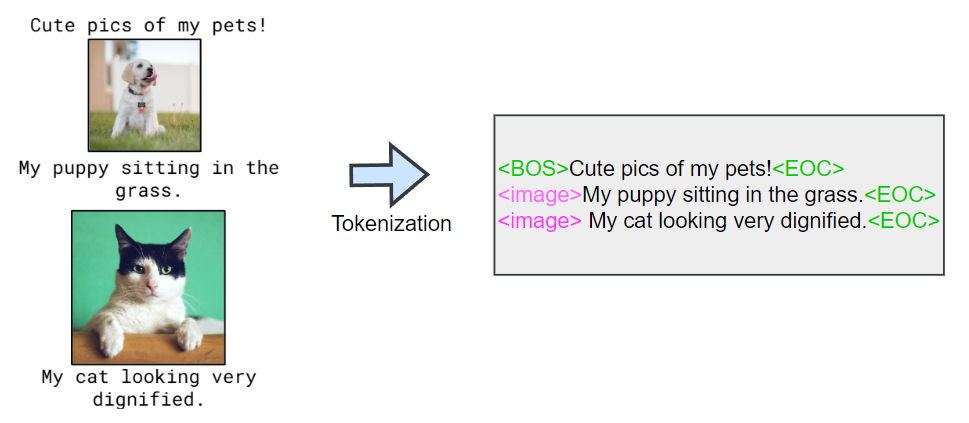
In the image, <EOC> is a newly introduced special token that represents “end of chunk”. It seems that each sentence ends with<EOC>, insinuating that “the sentence ends here, and image will come next.” <image> is a special token, serving as a placeholder. The tokenizer treats <image> as a single token. This placeholder tells where visual tokens should be inserted. When the model (or internal module) sees a <image>, it replaces the placeholder with visual embeddings.
Special Tokens for Temporal Grounding
 In the paper, Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning, they introduced a vision lanugage model architecture that generates a caption from a video input. One problem in video captioning is identifying essential events across video frames (i.e., temporal localization). To address this problem, the authors added 100 new special tokens to the tokenizer to let the model explicitly encode and generate time information. These special tokens represent the relative timestamps.
In the paper, Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning, they introduced a vision lanugage model architecture that generates a caption from a video input. One problem in video captioning is identifying essential events across video frames (i.e., temporal localization). To address this problem, the authors added 100 new special tokens to the tokenizer to let the model explicitly encode and generate time information. These special tokens represent the relative timestamps.
Special Tokens for Visual Grounding
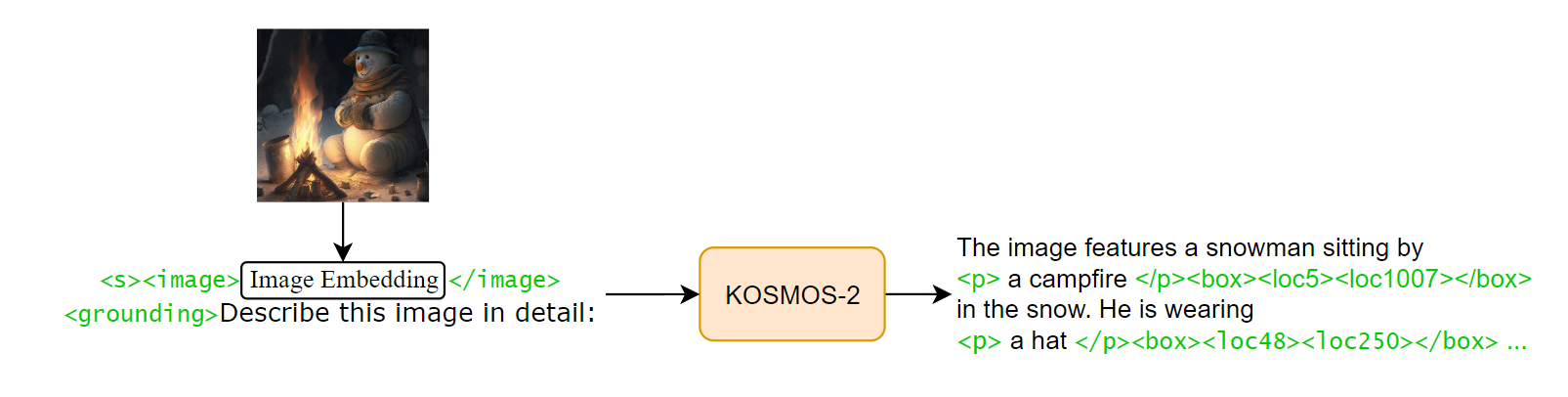 KOSMOS-2 is a multimodal LLM for visual grounding, where the model grounds region-of-interest descriptions to specific image areas. The authors introduced new special tokens:
KOSMOS-2 is a multimodal LLM for visual grounding, where the model grounds region-of-interest descriptions to specific image areas. The authors introduced new special tokens:
- grounding switch token:
<grounding> - text span tokens:
<p>,</p>, - boundary tokens:
<box>,</box> - \(32 \times 32\) spatial tokens:
<loc>
The grounding switch token (<grounding>) signals the model to ground the text output to specific regions in the visual input. If the input prompt does not include <grounding>, the model outputs textual response without visual grounding. The text span tokens (<p>, </p>) mark text spans, which are the targets for grounding to regions in the image. The boundary token represents a single bounding box, enclosing the spatial tokens. The spatial tokens (<loc>) represent discretized grid locations in the image.
Reading this paper, I asked myself “Why spatial tokens alone are not enough without text span tokens and boundary tokens?” I am not the author, but I can see a reason from an anology.
Let’s say you are looking at an example of bounding box.
example 1.
{
"image_id": 12345,
"category_id": 18,
"bbox": [50, 30, 200, 100],
"area": 20000,
"iscrowd": 0
}
example2.
This annotation describes an object in an image with ID 12345. The object belongs to category 18. It’s enclosed by a bounding box that starts at pixel coordinates (50, 30) in the image and measures 200 pixels wide and 100 pixels tall, covering an area of 20,000 pixels in total. The iscrowd value is 0, meaning the object is a single instance rather than a group of overlapping objects that would be difficult to separate.
Two examples talks about the same thing but why you feel easy when looking at example 1? When I see a list of x:y, it seems like there are multiple attributes in annotation. Secondly, I see four coordinates for bbox. I am already familar with the COCO format so I know [50, 30, 200, 100] represnts (top_left_x, top_left_y, width, height).
Essentially, example 1 offers better readability because it’s written in a format (an “agreement”) I’m familiar with. In the same way, if we give a model a new agreement (i.e., special tokens) the model can efficiently learn the pattern and adapt to the new structure. Better readability leads to better writability: the clearer the format, the more reliably the model can produce correct outputs.
Tokens like <p> and <box> might seem trivial. However, by adding these new special tokens, the author (model) create a consistent “grammar” for grounding, which makes it easier for the model to understand, learn, and generate grounded multimodal outputs accurately. The structure helps the model disambiguate which parts of text map to which regions in the image and prevents the chaos that could arise from a free-form token stream without clear boundaries.
Conclusion
In this blog, we explored several examples of how researchers add new special tokens to tokenizers in both language and multimodal models. My main observation from these examples is that special tokens are often expanded or introduced whenever the model needs to handle new types of structure, modalities, or tasks that go beyond plain text. Special tokens make it easier for models to learn, understand, and generate complex multimodal outputs accurately. Eventually, designing special tokens is like designing a new grammar for the model: it improves both how the model reads inputs and how it writes its outputs.